loki 性能优化和源码解读
前文提到我们部署了一个每秒处理日志 4 万条的 loki 集群,日志被收集至 kafka,promtail 负责消费 kafka 然后将日志发往 loki 集群。
这个过程中遇到了 promtail 两个性能问题
- cpu 使用率低,一直徘徊在 30% 左右
- Pipeline Stages 性能差
接下来详细介绍下我们是怎么解决的
性能优化
cpu 使用率低
kafka 5 个分区,promtail 5个实例,promtail 配置是 4c8g,每个实例 cpu 使用率都在 30% 左右。
分析代码我们发现
promtail 的原来的思路是
- 协程 A 从 kafka 拉取一批数据
- 解析完发给协程 B 去处理
- 协程 B 判断是否到达 1 秒间隔或者这批数据累积到 1MB,如果是就调用 api 将日志数据发往服务端
- 协程 B 等待 api 响应完成,才会继续处理下一批数据
这里相当于是同步消费 kafka 数据的,服务端写入性能快,promtail 消费速度就快,写入慢,消费速度就慢。这里存在的问题是,如果服务端(Ingester)写入性能差,比如说 平均 20ms,tp99 200ms,cpu 20%,会导致 promtail cpu 上不去。
举个形象的例子,ingester 本来能并发处理 30 个请求,但是每个请求需要耗时 20ms 才能处理完成,promtail 每次只会并发请求 1 个,服务端处理完 promtail 才会发起下一个请求
解决办法:通过协程池(类似 java 线程池)去发送 api,提升 promtail 消费 kafka 的速度,最终增加 promtail 并发请求数
具体代码修改如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
+ type BatchWorkerEntry struct {
+ batch *batch
+ tenantId string
+ }
func (c *client) run() {
batches := map[string]*batch{}
// Given the client handles multiple batches (1 per tenant) and each batch
// can be created at a different point in time, we look for batches whose
// max wait time has been reached every 10 times per BatchWait, so that the
// maximum delay we have sending batches is 10% of the max waiting time.
// We apply a cap of 10ms to the ticker, to avoid too frequent checks in
// case the BatchWait is very low.
minWaitCheckFrequency := 10 * time.Millisecond
maxWaitCheckFrequency := c.cfg.BatchWait / 10
if maxWaitCheckFrequency < minWaitCheckFrequency {
maxWaitCheckFrequency = minWaitCheckFrequency
}
maxWaitCheck := time.NewTicker(maxWaitCheckFrequency)
defer func() {
maxWaitCheck.Stop()
// Send all pending batches
for tenantID, batch := range batches {
c.sendBatch(tenantID, batch)
}
c.wg.Done()
}()
+ // 假设 `numWorkers` 是您想要启动的并行工作者(goroutines)的数量
+ numWorkers := 5
+ // 创建一个通道,用来分发工作项到工作者
+ batchChan := make(chan BatchWorkerEntry, numWorkers)
+ // 启动工作者goroutines
+ for i := 0; i < numWorkers; i++ {
+ go func(workerID int) {
+ for entry := range batchChan {
+ // 这里处理每个条目的逻辑
+ c.sendBatch(entry.tenantId, entry.batch)
+ }
+ }(i)
+ }
+
for {
select {
case e, ok := <-c.entries:
if !ok {
return
}
e, tenantID := c.processEntry(e)
// Either drop or mutate the log entry because its length is greater than maxLineSize. maxLineSize == 0 means disabled.
if c.maxLineSize != 0 && len(e.Line) > c.maxLineSize {
if !c.maxLineSizeTruncate {
c.metrics.droppedEntries.WithLabelValues(c.cfg.URL.Host, tenantID, ReasonLineTooLong).Inc()
c.metrics.droppedBytes.WithLabelValues(c.cfg.URL.Host, tenantID, ReasonLineTooLong).Add(float64(len(e.Line)))
break
}
c.metrics.mutatedEntries.WithLabelValues(c.cfg.URL.Host, tenantID, ReasonLineTooLong).Inc()
c.metrics.mutatedBytes.WithLabelValues(c.cfg.URL.Host, tenantID, ReasonLineTooLong).Add(float64(len(e.Line) - c.maxLineSize))
e.Line = e.Line[:c.maxLineSize]
}
batch, ok := batches[tenantID]
// If the batch doesn't exist yet, we create a new one with the entry
if !ok {
batches[tenantID] = newBatch(c.maxStreams, e)
c.initBatchMetrics(tenantID)
break
}
// If adding the entry to the batch will increase the size over the max
// size allowed, we do send the current batch and then create a new one
if batch.sizeBytesAfter(e) > c.cfg.BatchSize {
- c.sendBatch(tenantID, batch)
+ // 将条目发送到分发通道,其中工作者goroutines会接收它
+ batchChan <- BatchWorkerEntry{
+ batch: batch,
+ tenantId: tenantID,
+ }
batches[tenantID] = newBatch(c.maxStreams, e)
break
}
// The max size of the batch isn't reached, so we can add the entry
err := batch.add(e)
if err != nil {
level.Error(c.logger).Log("msg", "batch add err", "tenant", tenantID, "error", err)
reason := ReasonGeneric
if err.Error() == errMaxStreamsLimitExceeded {
reason = ReasonStreamLimited
}
c.metrics.droppedBytes.WithLabelValues(c.cfg.URL.Host, tenantID, reason).Add(float64(len(e.Line)))
c.metrics.droppedEntries.WithLabelValues(c.cfg.URL.Host, tenantID, reason).Inc()
return
}
case <-maxWaitCheck.C:
// Send all batches whose max wait time has been reached
for tenantID, batch := range batches {
if batch.age() < c.cfg.BatchWait {
continue
}
- c.sendBatch(tenantID, batch)
+ // 将条目发送到分发通道,其中工作者goroutines会接收它
+ batchChan <- BatchWorkerEntry{
+ batch: batch,
+ tenantId: tenantID,
+ }
delete(batches, tenantID)
}
}
}
}
Pipeline Stages 性能差
我们希望 kafka 分区数保持不变,通过提升 promtail 机器配置实现 promtail 消费速度的提升,所以将 promtail 从 4c8g 提升至 16c16g
观察发现,promtail 集群消费 kafka 速度有上升,从 60MB/s 提升至110MB/s,但是再也上不去了,cpu 使用率又停留在 30% 左右
通过 pprof 火焰图发现 processEntry 耗时很多,这是 promtail 的 Pipeline Stages 功能,可以通过配置化的方式从日志中提取 labels、时间戳,还可以指定新的日志内容
观察代码发现,Pipeline Stages 每个 stage 是同步处理的,一个步骤慢会影响下一个步骤
解决办法:我们让每个步骤由多个协程来处理,步骤和步骤间还是同步的,这样也能加快整体处理速度
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
// Run implements Stage
func (p *Pipeline) Run(in chan Entry) chan Entry {
in = RunWith(in, func(e Entry) Entry {
// Initialize the extracted map with the initial labels (ie. "filename"),
// so that stages can operate on initial labels too
for labelName, labelValue := range e.Labels {
e.Extracted[string(labelName)] = string(labelValue)
}
return e
})
// chain all stages together.
for _, m := range p.stages {
- in = m.Run(in)
+ in = runStageInParallel(in, m, 10)
}
return in
}
+ // parallelism 是你想要的并行goroutine的数量
+ func runStageInParallel(in chan Entry, stage Stage, parallelism int) chan Entry {
+ // 创建一个切片来存放所有输出通道
+ var outChans []chan Entry
+
+ for i := 0; i < parallelism; i++ {
+ outChans = append(outChans, stage.Run(in))
+ }
+
+ // 合并所有的输出通道到一个通道
+ return merge(outChans...)
+ }
+
+ func merge(channels ...chan Entry) chan Entry {
+ var wg sync.WaitGroup
+ out := make(chan Entry)
+
+ output := func(c chan Entry) {
+ defer wg.Done()
+ for n := range c {
+ out <- n
+ }
+ }
+
+ wg.Add(len(channels))
+ for _, c := range channels {
+ go output(c)
+ }
+
+ // 启动一个goroutine来关闭最终的输出通道
+ // 当所有的输入通道都关闭后
+ go func() {
+ wg.Wait()
+ close(out)
+ }()
+
+ return out
+ }
源码解读
loki 代码都在一个仓库,是怎么分功能部署的?
loki 有十几个组件,大致可以分为几个功能
- Distributor
- Ingester
- read
- backend
- store
他是怎么管理的呢?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
func (t *Loki) setupModuleManager() error {
mm := modules.NewManager(util_log.Logger)
mm.RegisterModule(Server, t.initServer, modules.UserInvisibleModule)
if t.Cfg.InternalServer.Enable {
mm.RegisterModule(InternalServer, t.initInternalServer, modules.UserInvisibleModule)
}
mm.RegisterModule(RuntimeConfig, t.initRuntimeConfig, modules.UserInvisibleModule)
mm.RegisterModule(MemberlistKV, t.initMemberlistKV, modules.UserInvisibleModule)
mm.RegisterModule(Ring, t.initRing, modules.UserInvisibleModule)
mm.RegisterModule(Overrides, t.initOverrides, modules.UserInvisibleModule)
mm.RegisterModule(OverridesExporter, t.initOverridesExporter)
mm.RegisterModule(TenantConfigs, t.initTenantConfigs, modules.UserInvisibleModule)
mm.RegisterModule(Distributor, t.initDistributor)
mm.RegisterModule(Store, t.initStore, modules.UserInvisibleModule)
mm.RegisterModule(Ingester, t.initIngester)
mm.RegisterModule(Querier, t.initQuerier)
mm.RegisterModule(IngesterQuerier, t.initIngesterQuerier)
mm.RegisterModule(QueryFrontendTripperware, t.initQueryFrontendMiddleware, modules.UserInvisibleModule)
mm.RegisterModule(QueryFrontend, t.initQueryFrontend)
mm.RegisterModule(RulerStorage, t.initRulerStorage, modules.UserInvisibleModule)
mm.RegisterModule(Ruler, t.initRuler)
mm.RegisterModule(RuleEvaluator, t.initRuleEvaluator, modules.UserInvisibleModule)
mm.RegisterModule(TableManager, t.initTableManager)
mm.RegisterModule(Compactor, t.initCompactor)
mm.RegisterModule(BloomCompactor, t.initBloomCompactor)
mm.RegisterModule(BloomCompactorRing, t.initBloomCompactorRing, modules.UserInvisibleModule)
mm.RegisterModule(IndexGateway, t.initIndexGateway)
mm.RegisterModule(IndexGatewayRing, t.initIndexGatewayRing, modules.UserInvisibleModule)
mm.RegisterModule(IndexGatewayInterceptors, t.initIndexGatewayInterceptors, modules.UserInvisibleModule)
mm.RegisterModule(BloomGateway, t.initBloomGateway)
mm.RegisterModule(BloomGatewayRing, t.initBloomGatewayRing, modules.UserInvisibleModule)
mm.RegisterModule(QueryScheduler, t.initQueryScheduler)
mm.RegisterModule(QuerySchedulerRing, t.initQuerySchedulerRing, modules.UserInvisibleModule)
mm.RegisterModule(Analytics, t.initAnalytics)
mm.RegisterModule(CacheGenerationLoader, t.initCacheGenerationLoader)
mm.RegisterModule(All, nil)
mm.RegisterModule(Read, nil)
mm.RegisterModule(Write, nil)
mm.RegisterModule(Backend, nil)
// Add dependencies
deps := map[string][]string{
Ring: {RuntimeConfig, Server, MemberlistKV},
Analytics: {},
Overrides: {RuntimeConfig},
OverridesExporter: {Overrides, Server},
TenantConfigs: {RuntimeConfig},
Distributor: {Ring, Server, Overrides, TenantConfigs, Analytics},
Store: {Overrides, IndexGatewayRing},
Ingester: {Store, Server, MemberlistKV, TenantConfigs, Analytics},
Querier: {Store, Ring, Server, IngesterQuerier, Overrides, Analytics, CacheGenerationLoader, QuerySchedulerRing},
QueryFrontendTripperware: {Server, Overrides, TenantConfigs},
QueryFrontend: {QueryFrontendTripperware, Analytics, CacheGenerationLoader, QuerySchedulerRing},
QueryScheduler: {Server, Overrides, MemberlistKV, Analytics, QuerySchedulerRing},
Ruler: {Ring, Server, RulerStorage, RuleEvaluator, Overrides, TenantConfigs, Analytics},
RuleEvaluator: {Ring, Server, Store, IngesterQuerier, Overrides, TenantConfigs, Analytics},
TableManager: {Server, Analytics},
Compactor: {Server, Overrides, MemberlistKV, Analytics},
IndexGateway: {Server, Store, IndexGatewayRing, IndexGatewayInterceptors, Analytics},
BloomGateway: {Server, BloomGatewayRing, Analytics},
BloomCompactor: {Server, BloomCompactorRing, Analytics},
IngesterQuerier: {Ring},
QuerySchedulerRing: {Overrides, MemberlistKV},
IndexGatewayRing: {Overrides, MemberlistKV},
BloomGatewayRing: {Overrides, MemberlistKV},
BloomCompactorRing: {Overrides, MemberlistKV},
MemberlistKV: {Server},
Read: {QueryFrontend, Querier},
Write: {Ingester, Distributor},
Backend: {QueryScheduler, Ruler, Compactor, IndexGateway, BloomGateway, BloomCompactor},
All: {QueryScheduler, QueryFrontend, Querier, Ingester, Distributor, Ruler, Compactor},
}
可以看到,他把这些功能按模块进行管理。
- 对于简单部署模式,他做了个归类, read/write/backend,分别启动。
- 对于单体部署模式,只要启动 all 就好
memberlist 的 join_members 怎么进行服务发现的?
配置示例
1
2
3
4
memberlist:
join_members:
# 使用 DNS A 记录进行查询,7946 是监听 gossip messages 的端口
- dns+loki-memberlist-lf.demo.local:7946
github.com/grafana/dskit/kv/memberlist/memberlist_client.go:707
从dns发现服务ip
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
// Provides a dns-based member disovery to join a memberlist cluster w/o knowning members' addresses upfront.
func (m *KV) discoverMembers(ctx context.Context, members []string) []string {
if len(members) == 0 {
return nil
}
var ms, resolve []string
for _, member := range members {
if strings.Contains(member, "+") {
resolve = append(resolve, member)
} else {
// No DNS SRV record to lookup, just append member
ms = append(ms, member)
}
}
err := m.provider.Resolve(ctx, resolve)
if err != nil {
level.Error(m.logger).Log("msg", "failed to resolve members", "addrs", strings.Join(resolve, ","), "err", err)
}
ms = append(ms, m.provider.Addresses()...)
return ms
}
github.com/grafana/dskit/dns/provider.go:117 根据地址解析出ip列表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
// Resolve stores a list of provided addresses or their DNS records if requested.
// Addresses prefixed with `dns+` or `dnssrv+` will be resolved through respective DNS lookup (A/AAAA or SRV).
// For non-SRV records, it will return an error if a port is not supplied.
func (p *Provider) Resolve(ctx context.Context, addrs []string) error {
resolvedAddrs := map[string][]string{}
errs := multierror.MultiError{}
for _, addr := range addrs {
var resolved []string
qtype, name := GetQTypeName(addr)
if qtype == "" {
resolvedAddrs[name] = []string{name}
continue
}
resolved, err := p.resolver.Resolve(ctx, name, QType(qtype))
p.resolverLookupsCount.Inc()
if err != nil {
// Append all the failed dns resolution in the error list.
errs.Add(err)
// The DNS resolution failed. Continue without modifying the old records.
p.resolverFailuresCount.Inc()
// Use cached values.
p.RLock()
resolved = p.resolved[addr]
p.RUnlock()
}
resolvedAddrs[addr] = resolved
}
// All addresses have been resolved. We can now take an exclusive lock to
// update the local state.
p.Lock()
defer p.Unlock()
p.resolved = resolvedAddrs
return errs.Err()
}
github.com/grafana/dskit/dns/resolver.go:54 A 记录的解析代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
func (s *dnsSD) Resolve(ctx context.Context, name string, qtype QType) ([]string, error) {
var (
res []string
scheme string
)
schemeSplit := strings.Split(name, "//")
if len(schemeSplit) > 1 {
scheme = schemeSplit[0]
name = schemeSplit[1]
}
// Split the host and port if present.
host, port, err := net.SplitHostPort(name)
if err != nil {
// The host could be missing a port.
host, port = name, ""
}
switch qtype {
case A:
if port == "" {
return nil, errors.Errorf("missing port in address given for dns lookup: %v", name)
}
ips, err := s.resolver.LookupIPAddr(ctx, host)
if err != nil {
// We exclude error from std Golang resolver for the case of the domain (e.g `NXDOMAIN`) not being found by DNS
// server. Since `miekg` does not consider this as an error, when the host cannot be found, empty slice will be
// returned.
if !s.resolver.IsNotFound(err) {
return nil, errors.Wrapf(err, "lookup IP addresses %q", host)
}
if ips == nil {
level.Error(s.logger).Log("msg", "failed to lookup IP addresses", "host", host, "err", err)
}
}
for _, ip := range ips {
res = append(res, appendScheme(scheme, net.JoinHostPort(ip.String(), port)))
}
哪些组件读写了一致性哈希环?
pkg/loki/config_wrapper.go:470
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// applyMemberlistConfig will change the default ingester, distributor, ruler, and query scheduler ring configurations to use memberlist.
// The idea here is that if a user explicitly configured the memberlist configuration section, they probably want to be using memberlist
// for all their ring configurations. Since a user can still explicitly override a specific ring configuration
// (for example, use consul for the distributor), it seems harmless to take a guess at better defaults here.
func applyMemberlistConfig(r *ConfigWrapper) {
r.Ingester.LifecyclerConfig.RingConfig.KVStore.Store = memberlistStr
r.Distributor.DistributorRing.KVStore.Store = memberlistStr
r.Ruler.Ring.KVStore.Store = memberlistStr
r.QueryScheduler.SchedulerRing.KVStore.Store = memberlistStr
r.CompactorConfig.CompactorRing.KVStore.Store = memberlistStr
r.IndexGateway.Ring.KVStore.Store = memberlistStr
r.BloomCompactor.Ring.KVStore.Store = memberlistStr
r.BloomGateway.Ring.KVStore.Store = memberlistStr
}
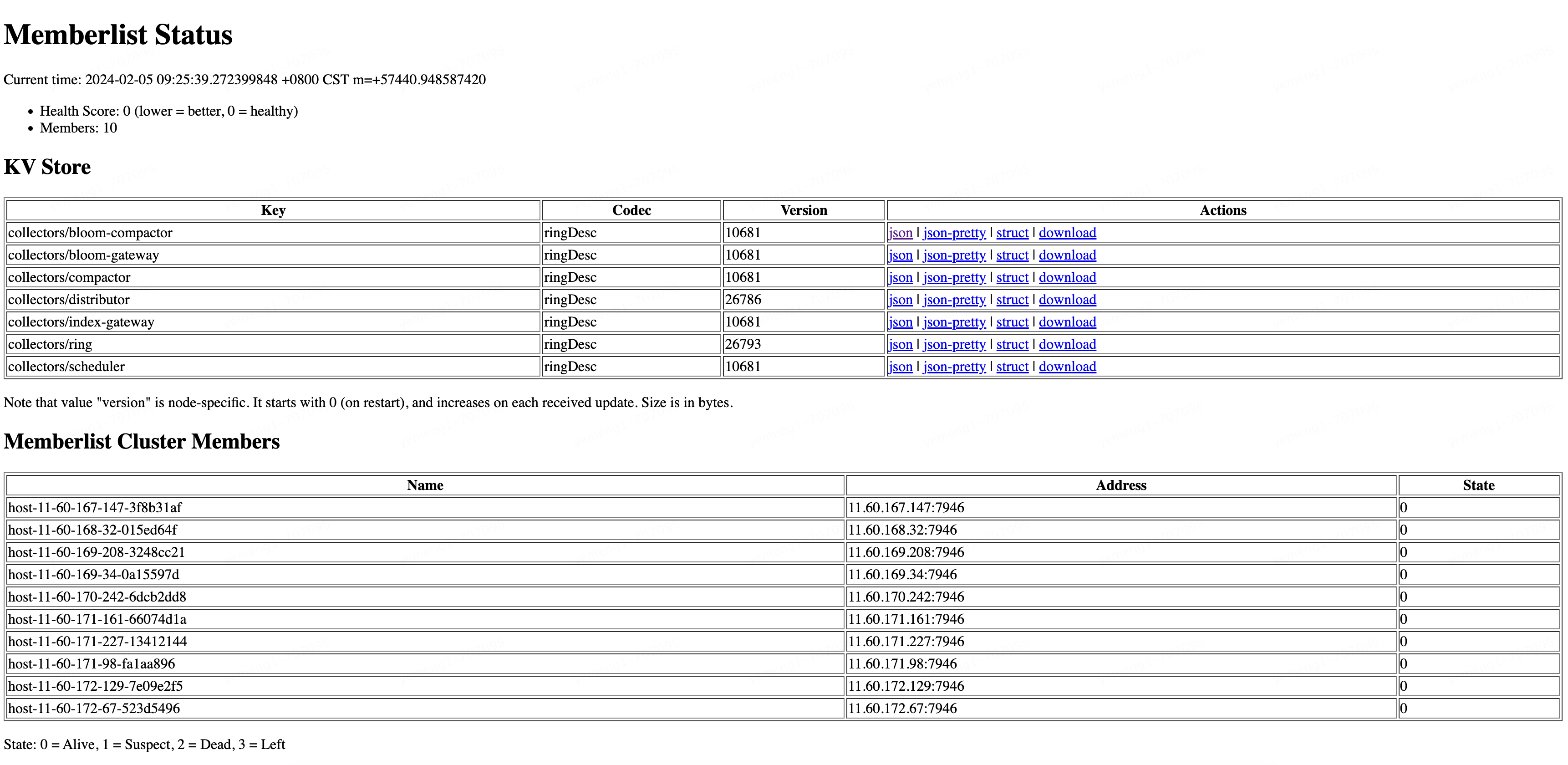
memberlist 里的数据能查看吗?
pkg/loki/modules.go:1167 注册 api 路由
1
2
3
4
5
6
7
8
func (t *Loki) initMemberlistKV() (services.Service, error) {
...
t.Server.HTTP.Handle("/memberlist", t.MemberlistKV)
if t.Cfg.InternalServer.Enable {
t.InternalServer.HTTP.Path("/memberlist").Methods("GET").Handler(t.MemberlistKV)
}
...
github.com/grafana/dskit/kv/memberlist/kv_init_service.go:88 实现 http 接口
1
2
3
func (kvs *KVInitService) ServeHTTP(w http.ResponseWriter, req *http.Request) {
NewHTTPStatusHandler(kvs, defaultPageTemplate).ServeHTTP(w, req)
}
github.com/grafana/dskit/kv/memberlist/http_status_handler.go:39 输出 html 页面的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
func (h HTTPStatusHandler) ServeHTTP(w http.ResponseWriter, req *http.Request) {
kv := h.kvs.getKV()
if kv == nil {
w.Header().Set("Content-Type", "text/plain")
// Ignore inactionable errors.
_, _ = w.Write([]byte("This instance doesn't use memberlist."))
return
}
const (
downloadKeyParam = "downloadKey"
viewKeyParam = "viewKey"
viewMsgParam = "viewMsg"
deleteMessagesParam = "deleteMessages"
)
api /memberlist
loki 日志写入逻辑
代码量太大,不便于阅读,我直接画流程图
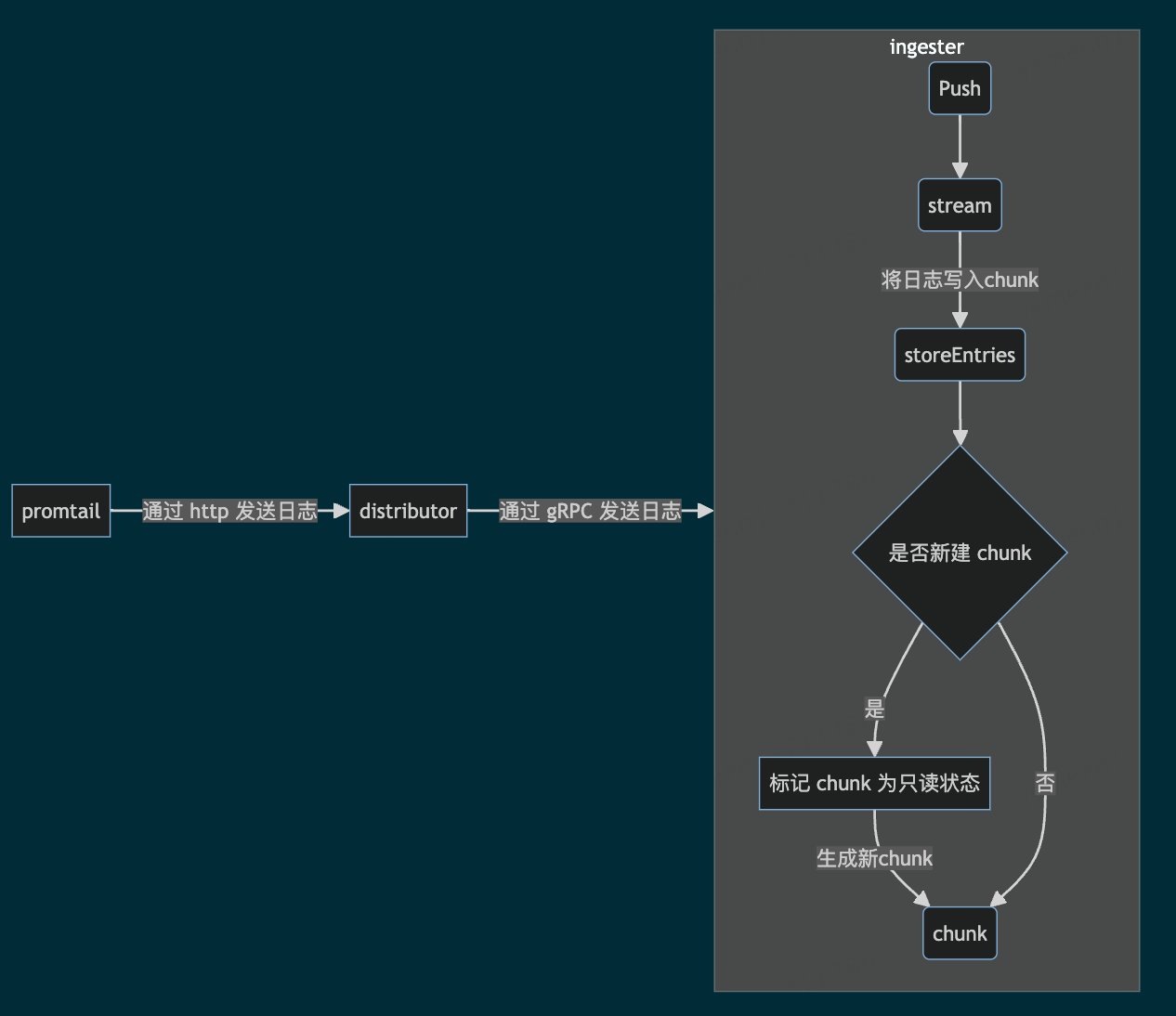
如果 replication_factor 是 3, 那么 distributor 会并行调用 3 个 ingester 写入数据
如果 chunk 写满了就会将原来的chunk标记为只读状态,并新建chunk
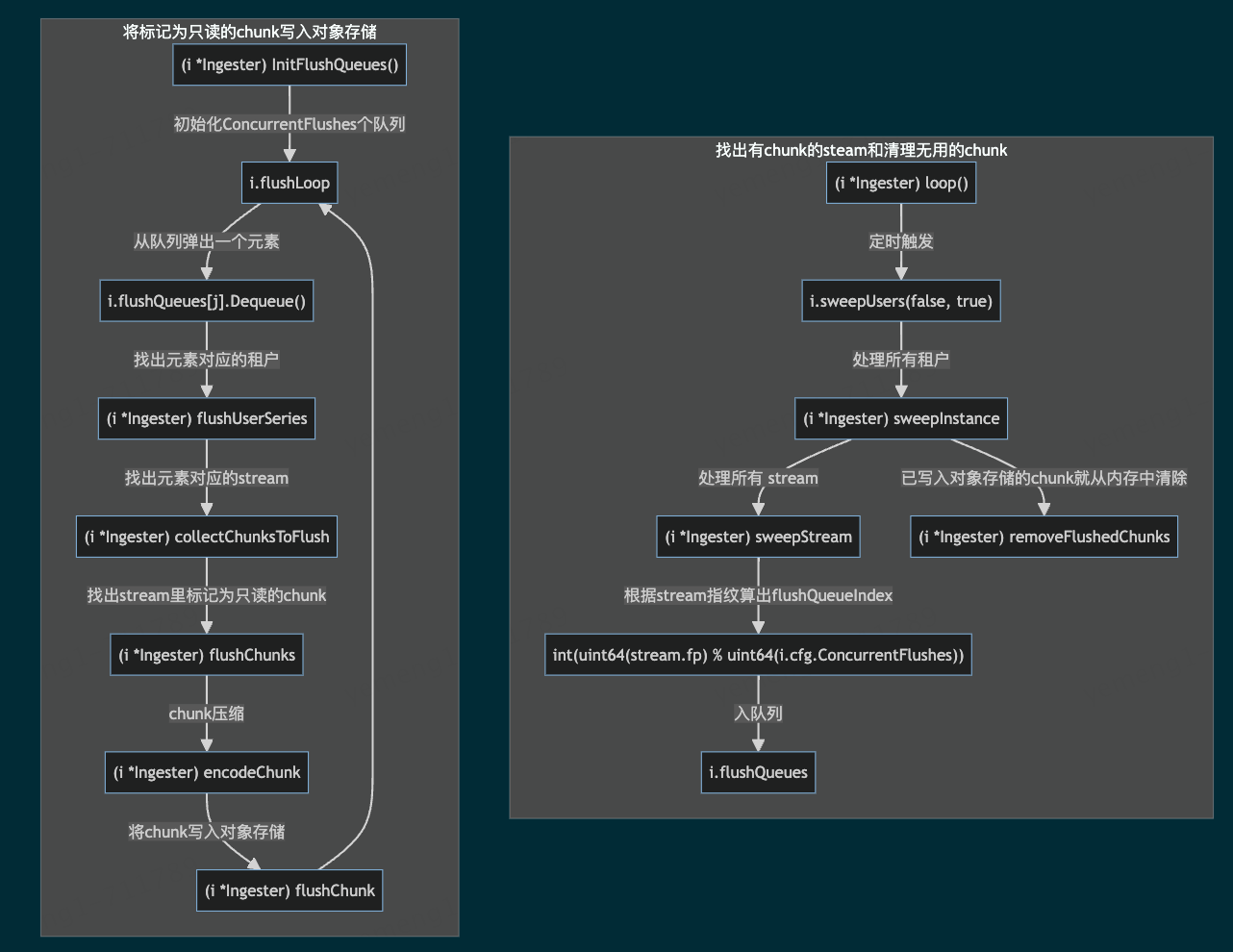
一个流程定时找出包含 chunk 的stream和清理内存中已经写入对象存储的chunk
一个流程循环将标记为只读状态的chunk写入对象存储