低存储成本+水平扩展+支持多租户的日志系统 loki 使用心得分享
Loki 架构介绍
loki 是可水平扩容、高可用、多租户的日志存储及查询系统,loki 设计目标是低成本运维、支持海量数据(每天 PB 级)
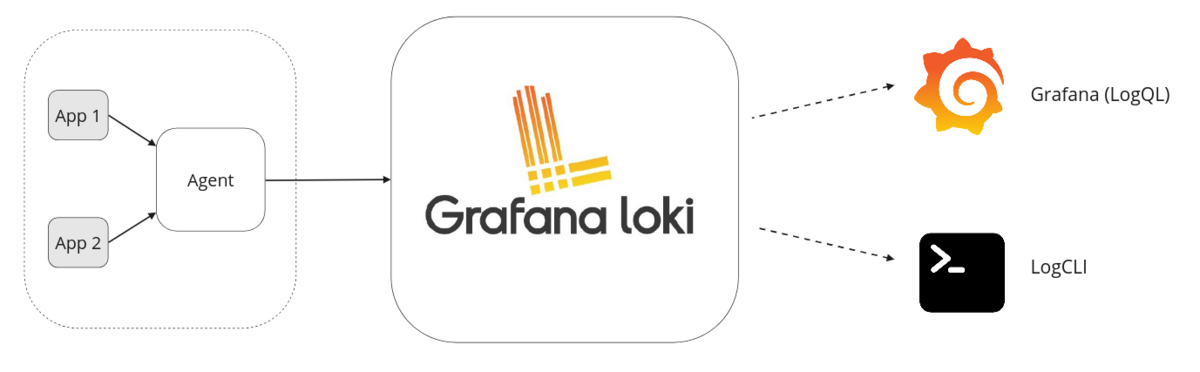
三个核心组件
- agent:例如 Promtail,用来抓取日志数据,并通过 HTTP api push 日志给 loki
- Loki:负责处理、存储、接收日志查询请求
- Grafana:负责日志数据的展示
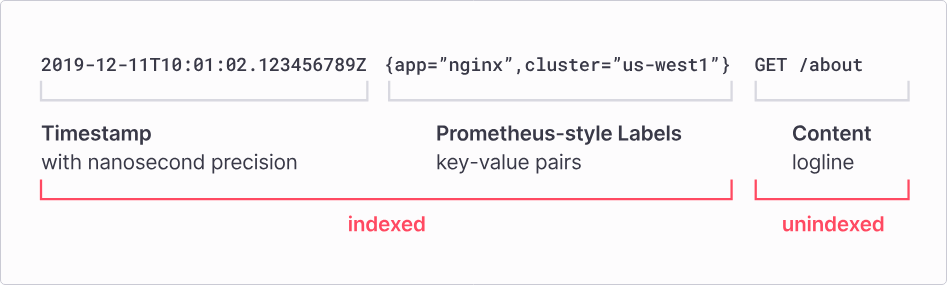 loki 将一条日志分为三部分。时间戳、labels、日志内容
loki 将一条日志分为三部分。时间戳、labels、日志内容
概念
- labels: 日志标签,后续可用来缩小日志查询范围,合格的日志标签例如 jdos 应用名称、jdos分组、color 接口名称,即标签值的范围是有限个数的,不能使用 pin 或者用户的 ip
数据读写路径
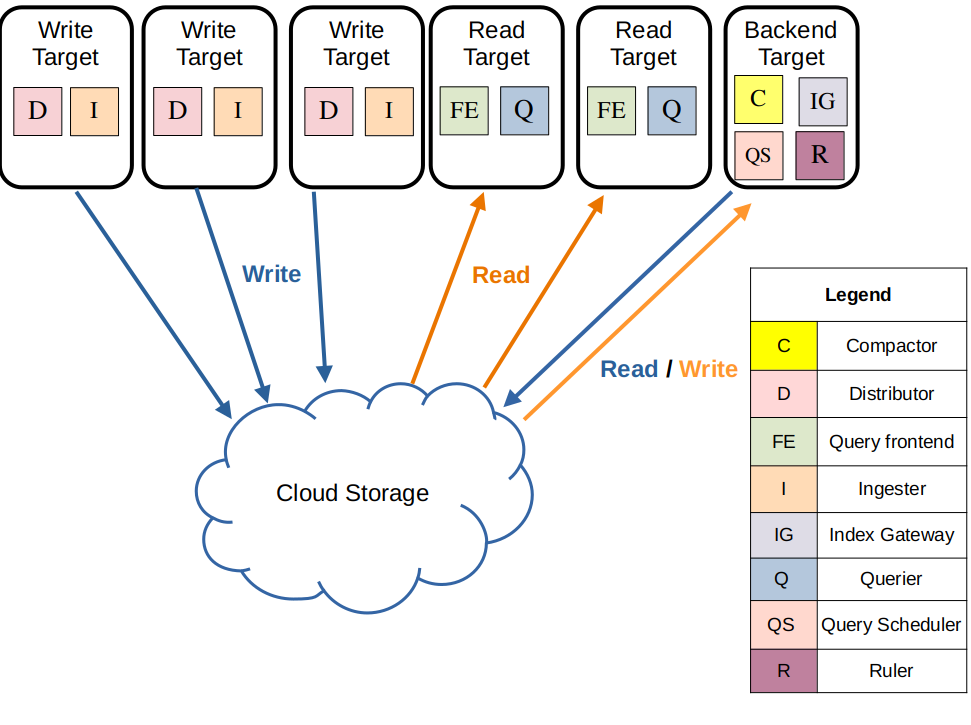
- Distributor 会对写入数据进行预处理,例如把 labels 进行排序,将
{foo="bar", bazz="buzz"}变成{bazz="buzz", foo="bar"}方便后续进行一致性hash,然后通过一致性哈希算法将日志发往 ingester 处理。还负责限速,流量过大时拒绝额外的请求 - ingester 创建日志分片和索引,最终转存到对象存储
- Query Frontend 具有查询拆分、缓存作用。一个查询会拆解成多个小查询,并行在多个 querier 组件上进行查询,最终合并返回给前端展示
- Querier 负责从 ingester 的内存中查询数据,如果没查到,就从对象存储中查询数据,因为replication factor的存在,数据可能重复,因此 querier 会进行数据去重
- Ruler 负责进行日志关键字告警
- Compactor 负责日志过期处理
Loki 数据存在哪?
loki 数据分为两种,索引和日志分片
- 索引数据,key/value结构,key 是日志 labels 的哈希,value 包含日志存在哪个分片(chunks)上、分片大小、日志时间范围等信息,以 TSDB 格式存储。15 分钟存一次对象存储
- 日志分片数据,压缩,存在对象存储中。Ingester 定期将日志分片存到对象存储中。
Loki 是如何保证数据高可用的?
核心是一致性哈希算法
针对每条日志,distributor 组件会根据他的 labels 算出来哈希值,根据 replication_factor(副本因子)去查找把日志数据发往哪些 ingesters,假设副本因子设为3,那么 quorum = floor(replication_factor / 2) + 1,即 2,如果少于 2 个 ingester 组件写入成功,这个请求就会失败,然后会重试,也就是说至多允许 1 个 ingester 写入失败
Replication factor 只是保证数据高可用的一种措施
ingester 组件还有 write ahead log (日志预写)功能,请求会先写入日志,哪怕进程崩溃,进程重启后也能够自动恢复数据
当一个日志分片(chunk)准备写入到对象存储时,chunk 基于租户id、labels、日志内容进行hash。 也就是说拥有相同日志数据的多个 ingester 只会往对象存储写入一份数据,但是如果这些副本中发生过日志写入失败的情况,哈希值会不一样,就会创建多份数据。
Querier 组件在查询数据时,先查询所有 Ingester 中的内存数据,没查到再去查对象存储,因为 replication_factor,querier 会收到重复的数据,因此querier 内部会进行去重,基于时间、labels、日志内容
loki 能不能水平扩缩容?
可以。
从写入路径看,主要涉及 distributor 和 ingester 组件
- distributor 无状态,可水平扩容
- ingester 有状态,但是也可以水平扩容,扩容后机器会自动注册到一致性哈希环中,增大集群的日志处理能力
从读取路径看,主要涉及 query Frontend 和 querier 组件,这两个都是无状态的,可根据查询数据量大小水平扩容
部署一个每秒处理4万条日志的集群
查询效果见 
支持实时日志,通过 websocket 协议接收数据 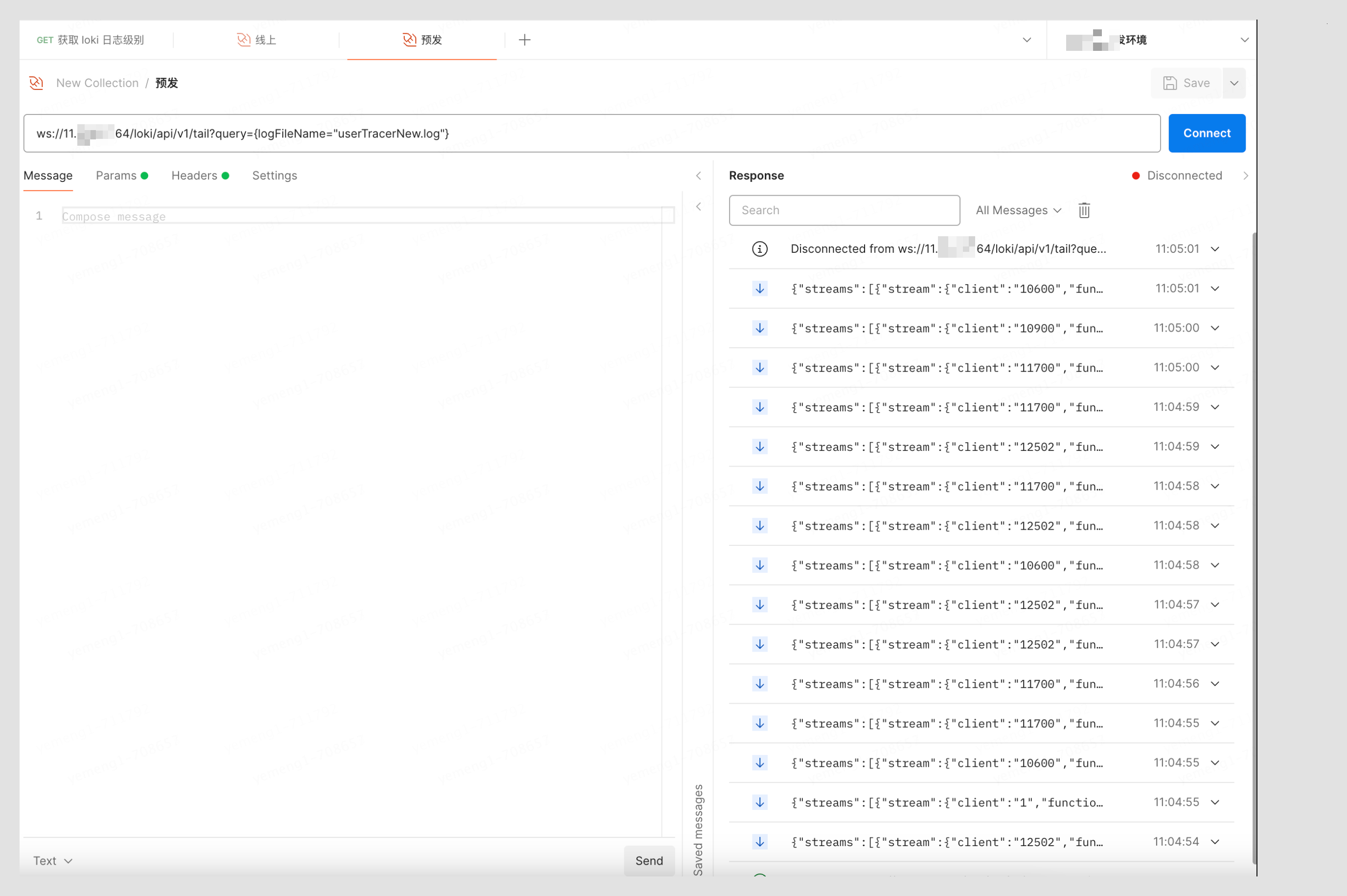
| 服务 | 配置 | 机器数量 | 备注 |
|---|---|---|---|
| promtail | 16c16g | 5 | 吃cpu |
| ingester | 1c8g | 180 | 吃内存 |
| distributor | 8c8g | 14 | 吃cpu |
| read | 16c32g | 1 | 吃cpu、内存、网络带宽 |
| store | 1c2g | 3 | 啥也不吃 |
经压测,kafka 5 个分区,promtail 消费速度是 250MB/s,日志处理量 4.16万条/s,对象存储写入 qps 150
常见问题
distributor 与 ingeser 是怎么通信的?
distributor 组件使用一致性哈希算法确定stream应该发往哪个ingester实例,通过 gRPC 协议发送数据
哈希环默认的实现是 memberlist,基于开源库 https://github.com/hashicorp/memberlist。底层通过 https://en.wikipedia.org/wiki/Gossip_protocol 实现数据的最终一致性。
租户id+每个标签key/value组合会唯一定一个stream,然后会算出一个哈希值(一个无符号的32位数字)
所有的 ingester 实例会将自己+对应的token集合注册到哈希环中,每个token是一个随机的无符号32位数字。
为了进行哈希查找,distributor 会先找到最小的 token,token 的值大于 stream 的哈希值。当 replication factor 大于 1 时,顺时针查找下一个 token 对应的不同 ingester 实例
这种机制的效果是:每个 ingester 拥有的 tokens 集合对应一串哈希范围。例如有3个tokens,分别是 0、25、50,stream 哈希值为 3 会被分配给拥有token 25 的ingester实例,拥有token 25 的ingester 实例负责 1-25 范围的哈希值
ingester 接收到的每个 stream 会生成一系列的 chunks,放在内存中,然后按固定间隔或者固定大小写入对象存储
chunks 被压缩和标记为只读仅当如下情况发生 当前 chunk 到达容量,chunk_target_size 当前 chunk 太长时间没有数据写入了 flush 操作发生(写入对象存储)
日志乱序咋处理?
Loki 默认支持日志乱序(同一个labels 的日志)。max_chunk_age 配置项默认2个小时
1
time_of_most_recent_line - (max_chunk_age/2)
即,这个 chunk 最新日志的时间是 8:00,max_chunk_age 设置为 2 个小时,则 Loki 最多能接受 7:00 之后的日志,6:55 的日志就丢弃了
比如说,chunk 最新日志的时间是 10:00,max_chunk_age 设置为 2 个小时,则 Loki 最多能接受 9:00 之后的日志, 8:55 的日志就丢弃了
多老的日志能被存储?
老日志默认会被丢弃
reject_old_samples: true
最多能接受多老的日志?默认一周,即最多接受一周前的日志
reject_old_samples_max_age: 1w
对象存储上文件多大一个?
对象存储上的文件分为 index 文件和日志内容(chunks)文件
一个 chunk(日志内容) 包含很多 block,格式如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
-------------------------------------------------------------------
| | |
| MagicNumber(4b) | version(1b) |
| | |
-------------------------------------------------------------------
| block-1 bytes | checksum (4b) |
-------------------------------------------------------------------
| block-2 bytes | checksum (4b) |
-------------------------------------------------------------------
| block-n bytes | checksum (4b) |
-------------------------------------------------------------------
| #blocks (uvarint) |
-------------------------------------------------------------------
| #entries(uvarint) | mint, maxt (varint) | offset, len (uvarint) |
-------------------------------------------------------------------
| #entries(uvarint) | mint, maxt (varint) | offset, len (uvarint) |
-------------------------------------------------------------------
| #entries(uvarint) | mint, maxt (varint) | offset, len (uvarint) |
-------------------------------------------------------------------
| #entries(uvarint) | mint, maxt (varint) | offset, len (uvarint) |
-------------------------------------------------------------------
| checksum(from #blocks) |
-------------------------------------------------------------------
| metasOffset - offset to the point with #blocks |
-------------------------------------------------------------------
每个 block 的大小由 ingester.chunk_block_size控制,默认 256KB
每个 chunk 文件大小由 ingester.chunk_target_size 控制,默认 1.5 MB ,由于是压缩的,所以最终文件大小不是很精确,或多或少 max_chunk_age(默认 2h) 和 chunk_idle_period(默认30分钟)也会影响最终 chunk 文件的大小,可能没有写满 1.5 MB
压缩算法默认使用 gzip,实际测试 snappy 性能最好
index 文件大小不一定。TSDB Manager 周期性的,15分钟一次,从 WALs 中生成 TSDBs,只要 labels 种类不多,index 一般不大
取决于压缩等级,原始日志大小可能是 7.5-10MB 或者 5-10倍大小,才能压缩成 1.5MB大小的 chunk 文件
一个 stream会产生多个chunks,labels 组合越多,stream 越多,Ingester 组件内存驻留的 chunk 越多,chunk 没写满的可能性越大。许多小的、没写满的 chunk 会让 loki 性能变差。
当某一个 stream 写入速率过快,怎么处理?
当某一个 stream 写入速率过快,可能会达到 per_stream_rate_limit(默认每秒 3MB),导致数据丢失,这种情况解决办法如下
- 看看有没有可以挖掘的 label,label 能作为查询条件,且基数低(这个 label 的值的种类少)。增加了新的 label,stream 数量就会增加,原始的 stream 就被分流了,这样新的 stream 的写入速度就会降低
- 开启自动分片功能,automatic stream sharding
自动分片实现原理,Ingester 组件会通过 api 暴露 stream 的写入速率,distributor 组件会查询该数据确定是否要生成新的分片,底层通过添加一个新的 label,__stream_shard__,要生成新的分片了,该label的值递增1,通过这个 label 来实现 stream 的分片
日志分割怎么应对?
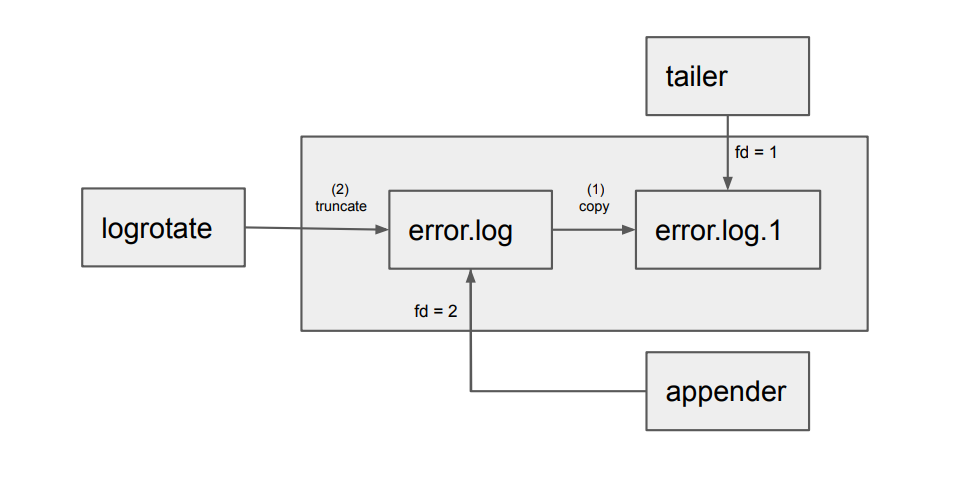
日志分割有两种模式
复制+清空
重命名+创建
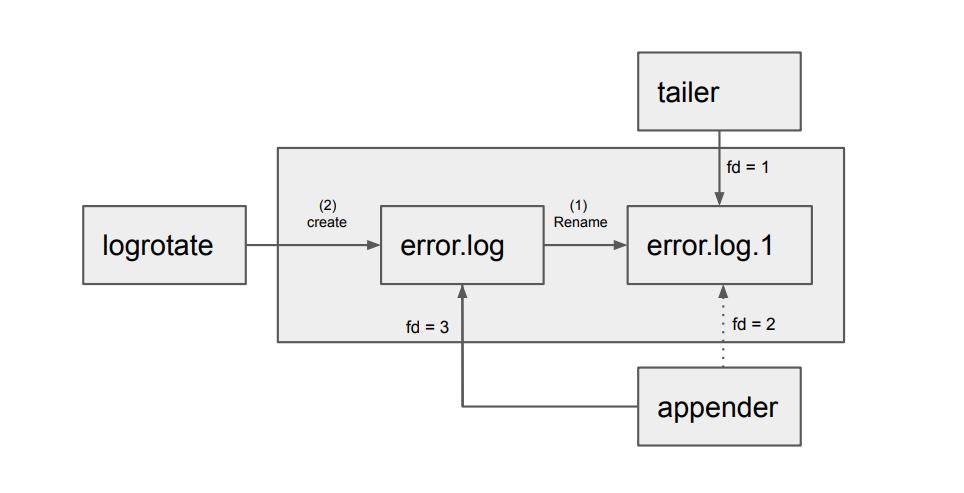 推荐使用重命名+创建,这样不会有日志数据丢失
推荐使用重命名+创建,这样不会有日志数据丢失
未来待优化的问题
目前 ingester 组件内存使用率不均匀,有的 70%多,有的才20%,因为是一致性哈希,相同labels哈希的日志会固定发往某些 ingeser 机器处理,这样某些 labels 的日志如果流量很大,就会导致部分机器内存使用率高,甚至导致内存爆掉进程崩溃
未来做日志流量分发时,得考虑机器的负载情况
当前临时解决办法
- 对 streams 限速,这样即使日志量很大,也不会导致机器崩溃
- 增加机器数量,增大机器内存
- 避免使用数据量很少的 labels,有些 labels 数据少,写入不均衡,导致 chunk 写不满,就无法及时写入对象存储,驻留内存太多,会导致机器内存爆掉
- flush_check_period,缩小间隔,及时将已写满的 chunk 写入对象存储
- chunk_idle_period,缩小闲置时间,1分钟没有数据写入的 chunk 就关闭写入,写入对象存储
- chunk_retain_period,缩小内存驻留时间,chunk 写入对象存储后,为了日志查询速度,默认会在内存驻留一段时间,后续查询时默认先从ingester组件查,没有再从对象存储下载
总结
loki 有两个特色我觉得比较好
- 最新版本存储只依赖对象存储,架构简单,不再需要 Cassandra 或者 etcd
- 支持模糊查询,无需提前建索引,支持实时日志
运维整个集群还是有点难度的,内存消耗也不小,开源版本没有自己的租户管理系统,只是能把数据分租户存储和查询。
Comments powered by Disqus.